Miruna Pîslar

About
I’m a Research Engineer at Google DeepMind in Paris, where I’m part of the AI for Education team.
My current research focuses on LearnLM, a pedagogical LLM for online tutoring. I work on training strategies, evaluation frameworks, and student simulators to advance AI tutoring systems.
In the past, I’ve worked on AI for Democracy, multi-agent systems, and exploration in reinforcement learning. More broadly, my interests span AI for social good, AI governance, and language evolution.
Outside of research, I think about society and enjoy engaging with different forms of art. I read, write, and create visual art.
Featured Projects
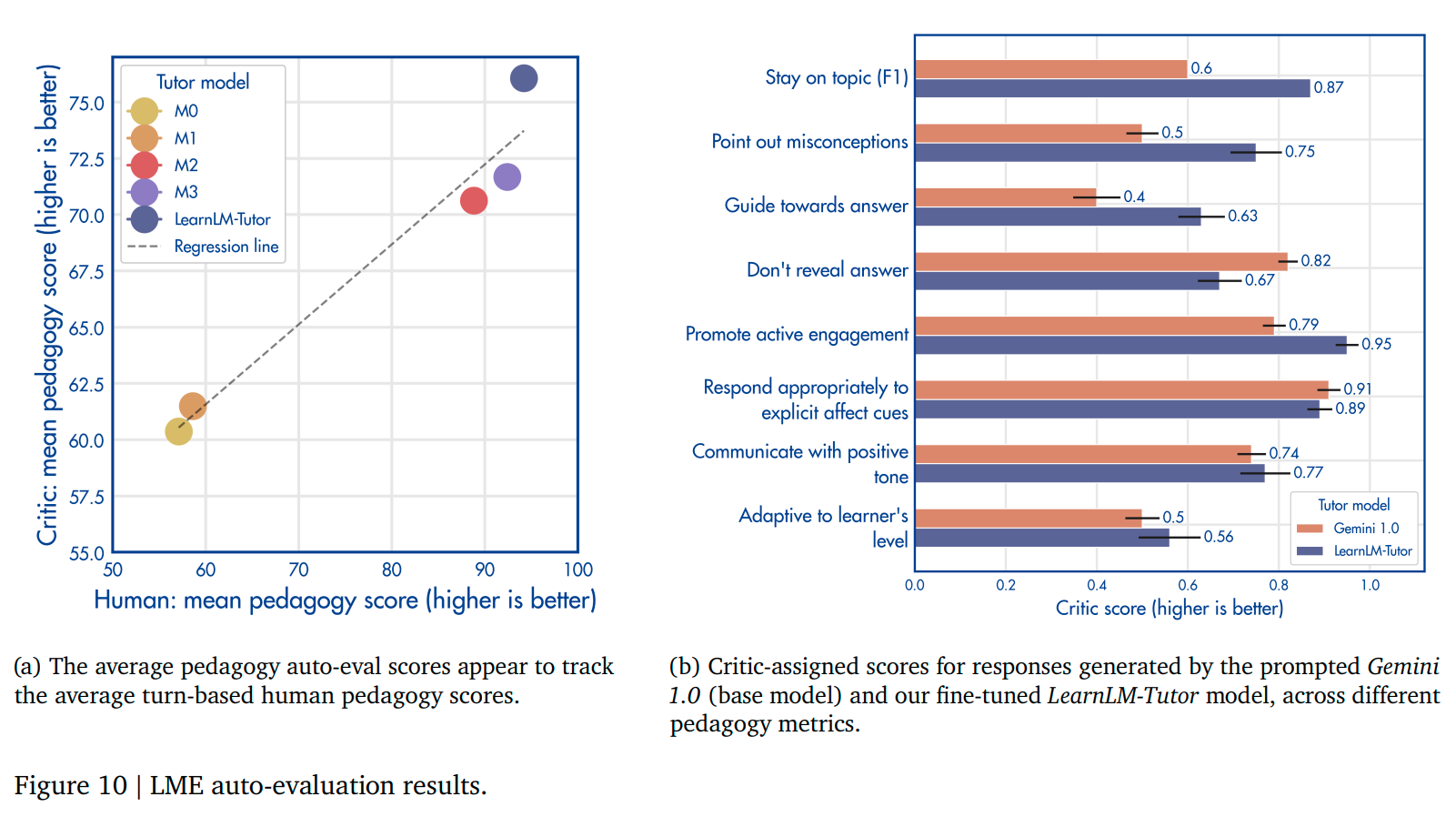
Towards Responsible Development of Generative AI for Education: An Evaluation-Driven Approach [paper] [LearnLM: Google IO announceement] [Learning Coach Gem] [demo]

Abstract: Grounded in educational research and tailored to how people learn, LearnLM represents an effort across Google DeepMind, Google Research and our product teams to help make learning experiences more engaging, personal and useful. Our technical report presents our approach to improving generative AI for education and highlights how we’re working together with the AI and EdTech communities to responsibly maximize its positive impact and potential.
Working alongside educators and other learning experts, we’re infusing learning science principles, like the following, into our models and the products they power:
- Inspire active learning: Allow for practice and healthy struggle with timely feedback
- Manage cognitive load: Present relevant, well-structured information in multiple modalities
- Adapt to the learner: Dynamically adjust to goals and needs, grounding in relevant materials
- Stimulate curiosity: Inspire engagement to provide motivation through the learning journey
- Deepen metacognition: Plan, monitor and help the learner reflect on progress
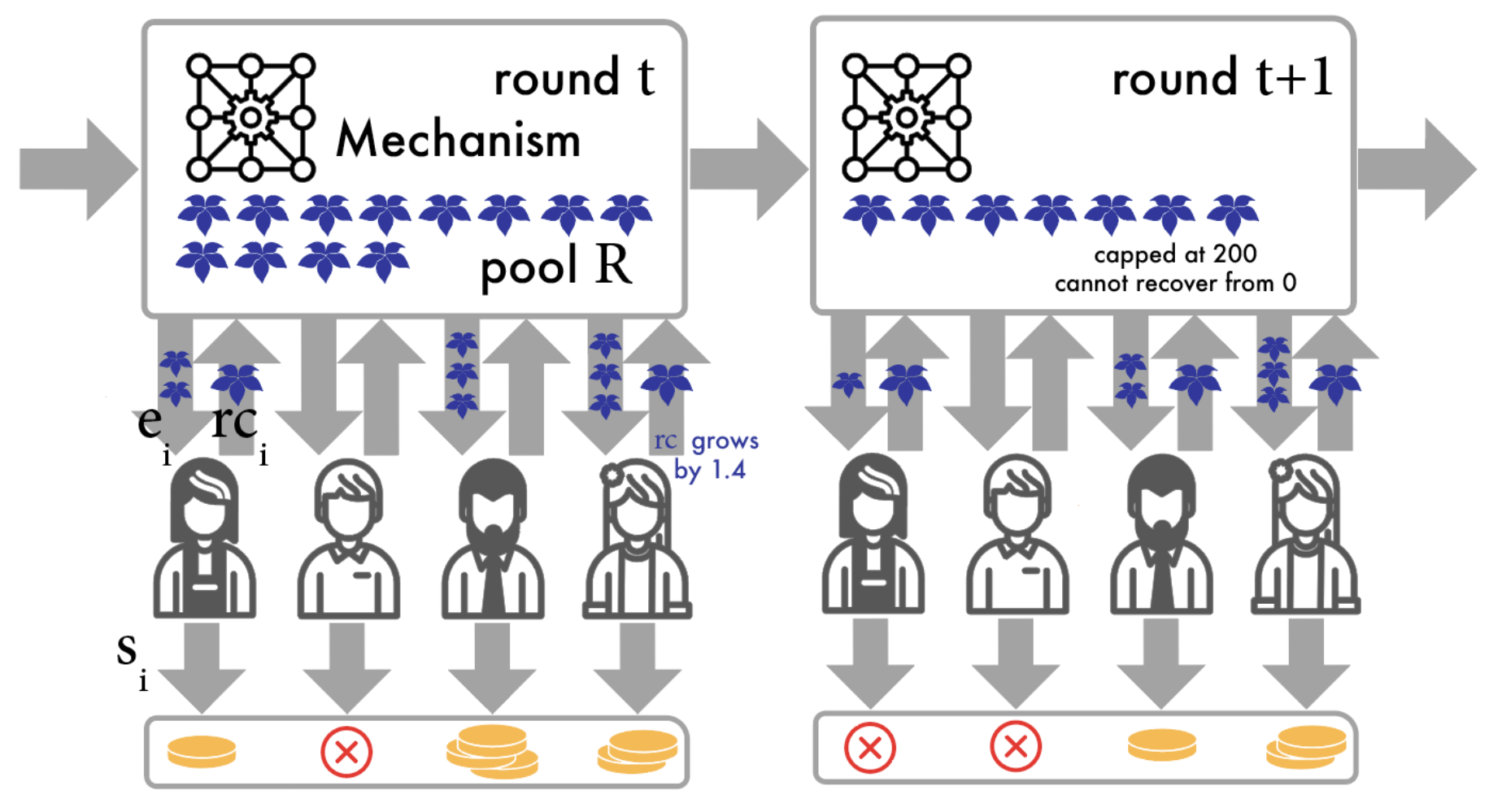
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem [paper]
Abstract: A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
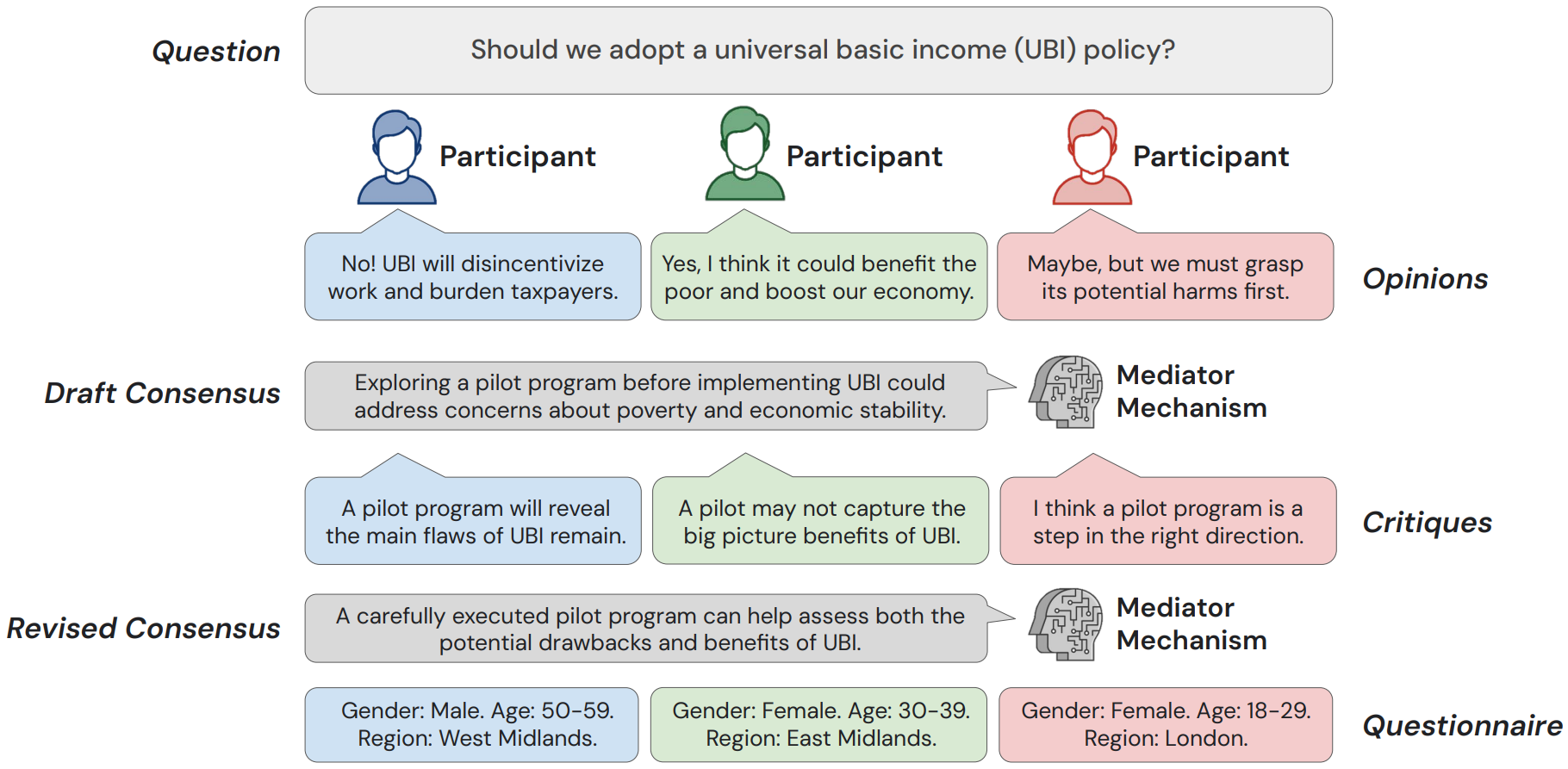
Language Models as Digital Representatives (LLMs) [paper]
Abstract: Consider the process of collective decision-making, in which a group of individuals interactively select a preferred outcome from among a universe of alternatives. In this context, “representation” is the activity of making an individual’s preferences present in the process via participation by a proxy agent—i.e. their “representative”. To this end, learned models of human behavior have the potential to fill this role, with practical implications for multi-agent scenario studies and mechanism design. In this work, we investigate the possibility of training language agents to behave in the capacity of representatives of human agents, appropriately expressing the preferences of those individuals whom they stand for. First, we formalize the setting of collective decision-making—as the episodic process of interaction between a group of agents and a decision mechanism. On this basis, we then formalize the problem of digital representation—as the simulation of an agent’s behavior to yield equivalent outcomes from the mechanism. Finally, we conduct an empirical case study in the setting of consensus-finding among diverse humans, and demonstrate the feasibility of fine-tuning large language models to act as digital representatives.
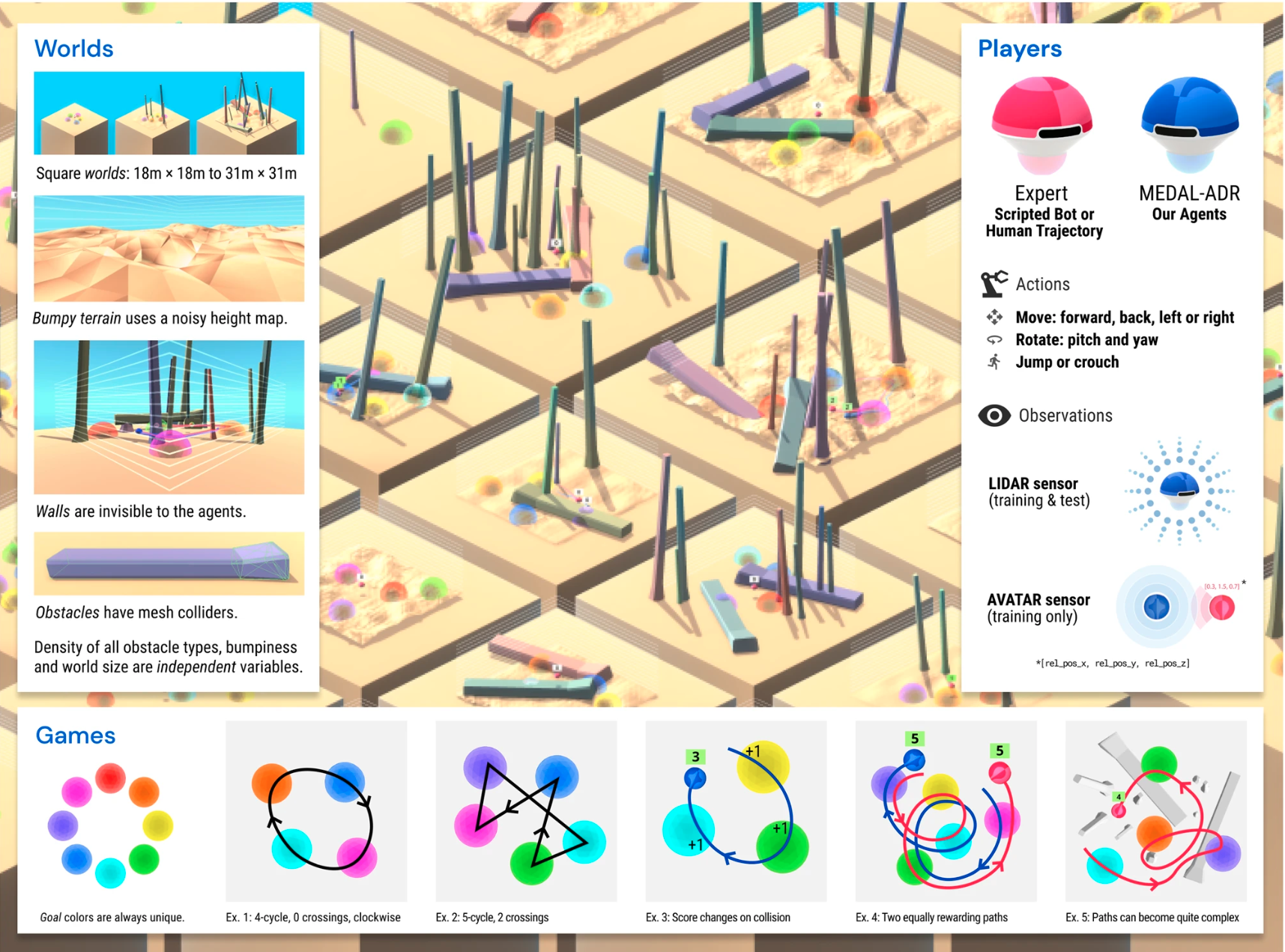
Social Learning (multi-agent RL) [Nature Comms] [arxiv] [blog post] [video website]
Abstract: Cultural transmission is the domain-general social skill that allows agents to acquire and use information from each other in real-time with high fidelity and recall. It can be thought of as the process that perpetuates fit variants in cultural evolution. In humans, cultural evolution has led to the accumulation and refinement of skills, tools and knowledge across generations. We provide a method for generating cultural transmission in artificially intelligent agents, in the form of few-shot imitation. Our agents succeed at real-time imitation of a human in novel contexts without using any pre-collected human data. We identify a surprisingly simple set of ingredients sufficient for generating cultural transmission and develop an evaluation methodology for rigorously assessing it. This paves the way for cultural evolution to play an algorithmic role in the development of artificial general intelligence.
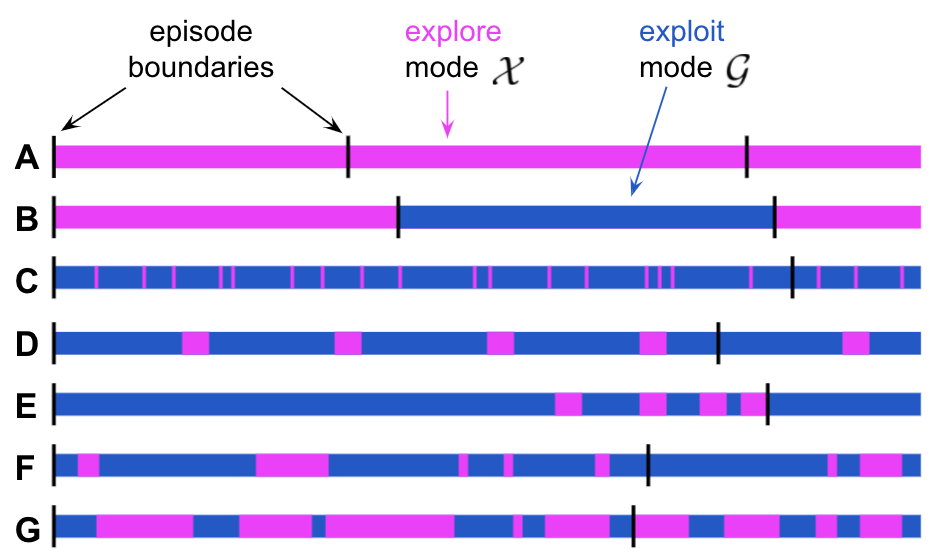
The when of exploration (RL) [paper] [ICLR spotlight] [poster]
![[poster]](https://raw.githubusercontent.com/MirunaPislar/MirunaPislar.github.io/main/assets/img/iclr-poster.png){kind=link}
Abstract: Exploration remains a central challenge for reinforcement learning (RL). Virtually all existing methods share the feature of a monolithic behaviour policy that changes only gradually (at best). In contrast, the exploratory behaviours of animals and humans exhibit a rich diversity, namely including forms of switching between modes. We present an initial study of mode-switching, non-monolithic exploration for RL. We investigate different modes to switch between, at what timescales it makes sense to switch, and what signals make for good switching triggers. We also propose practical algorithmic components that make the switching mechanism adaptive and robust, which enables flexibility without an accompanying hyper-parameter-tuning burden.
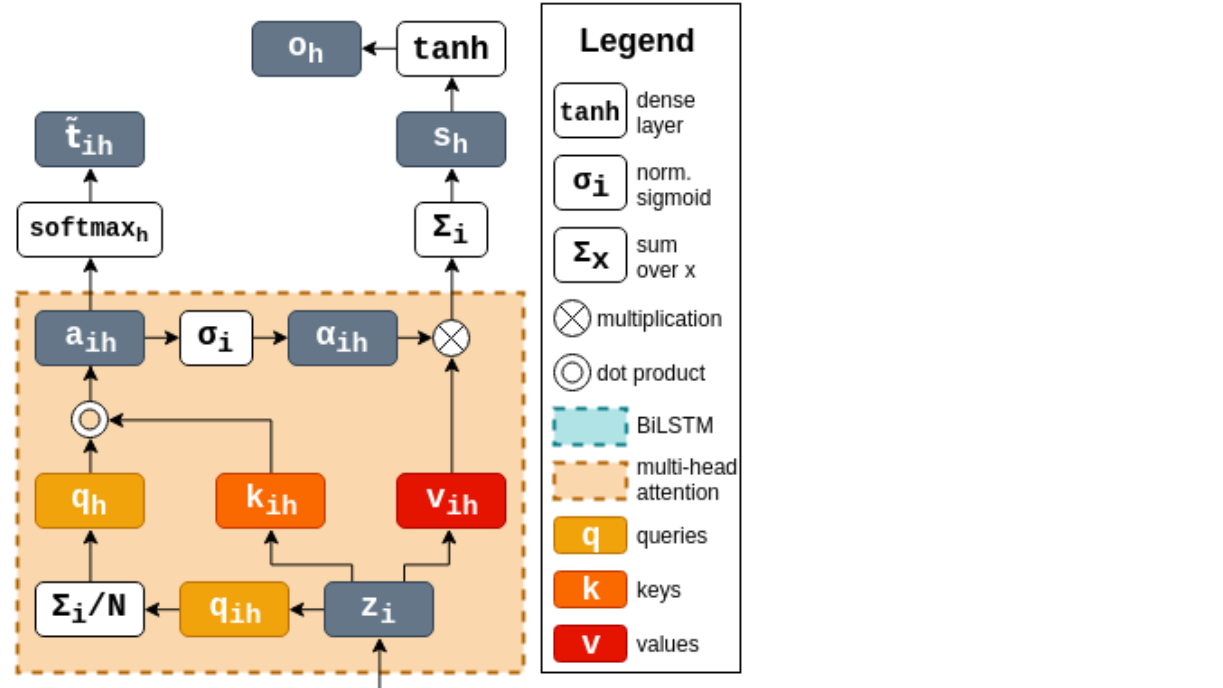
Multi-head attention for hierarchical text labelling (MPhil dissertation) [paper] [code]
Abstract: In natural languages, words are used in association to construct sentences. It is not words in isolation, but the appropriate combination of hierarchical structures that conveys the meaning of the whole sentence. Neural networks can capture expressive language features; however, insights into the link between words and sentences are difficult to acquire automatically. In this work, we design a deep neural network architecture that explicitly wires lower and higher linguistic components; we then evaluate its ability to perform the same task at different hierarchical levels.
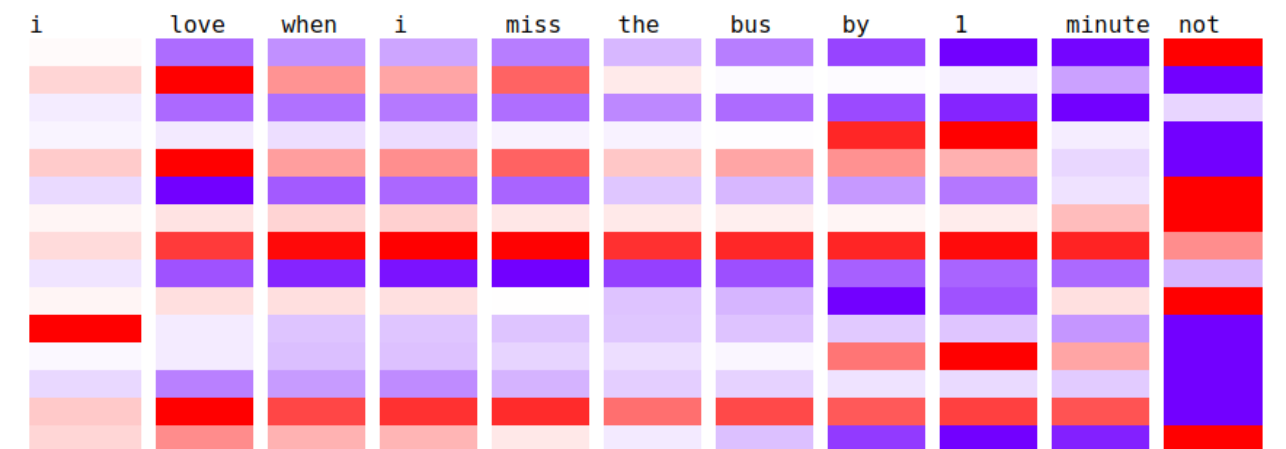
Sarcasm detection (BSc dissertation) [code] [youtube video]
Abstract: At a first, superficial glance, sarcasm might not seem representative of our individuality so as to require much attention from the research community, but a closer look would convince anyone that its sentiment, social and behavioural implications provide essential information about the way humans have historically built their ‘feelings’ and personality in response to the surrounding environment and their daily interactions. We propose an attention-based LSTM model to detect sarcasm in tweets and analyse the learned features to help our human (and therefore limited) understanding of sarcasm.
Publications
Evaluating Gemini in an arena for learning. LearnLM Team, Google. arXiv (2025).
Learnlm: Improving gemini for learning. LearnLM Team, Google. arXiv (2025).
Towards Responsible Development of Generative AI for Education: An Evaluation-Driven Approach. Irina Jurenka*, Markus Kunesch*, Kevin R. McKee, Daniel Gillick, Shaojian Zhu, Sara Wiltberger, Shubham Milind Phal, Katherine Hermann, Daniel Kasenberg, Avishkar Bhoopchand, Ankit Anand, Miruna Pîslar, Stephanie Chan, Lisa Wang, Jennifer She, Parsa Mahmoudieh, Aliya Rysbek, Wei-Jen Ko, et al. arXiv (2024).
Deep reinforcement learning can promote sustainable human behaviour in a common-pool resource problem. Raphael Koster*, Miruna Pîslar*, Andrea Tacchetti, Jan Balaguer, Leqi Liu, Romuald Elie, Oliver P. Hauser, Karl Tuyls, Matt Botvinick, Christopher Summerfield. Nature Communications (2025).
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem. Raphael Koster*, Miruna Pîslar*, Andrea Tacchetti, Jan Balaguer, Leqi Liu, Romuald Elie, Oliver P. Hauser, Karl Tuyls, Matt Botvinick, Christopher Summerfield. arXiv (2024).
Language Agents as Digital Representatives in Collective Decision-Making. Daniel Jarrett*, Miruna Pîslar*, Michael Tessler, Michiel Bakker, Raphael Koster, Jan Balaguer, Romuald Elie, Christopher Summerfield, Andrea Tacchetti. FMDM Workshop at NeurIPS (2023).
Learning few-shot imitation as cultural transmission. Avishkar Bhoopchand*, Bethanie Brownfield*, Adrian Collister*, Agustin Dal Lago*, Ashley Edwards*, Richard Everett*, Alexandre Fréchette*, Yanko Gitahy Oliveira*, Edward Hughes*, Kory W. Mathewson*, Piermaria Mendolicchio*, Julia Pawar*, Miruna Pȋslar*, Alex Platonov*, Evan Senter*, Sukhdeep Singh*, Alexander Zacherl*, Lei M. Zhang*. Nature Communications (2023).
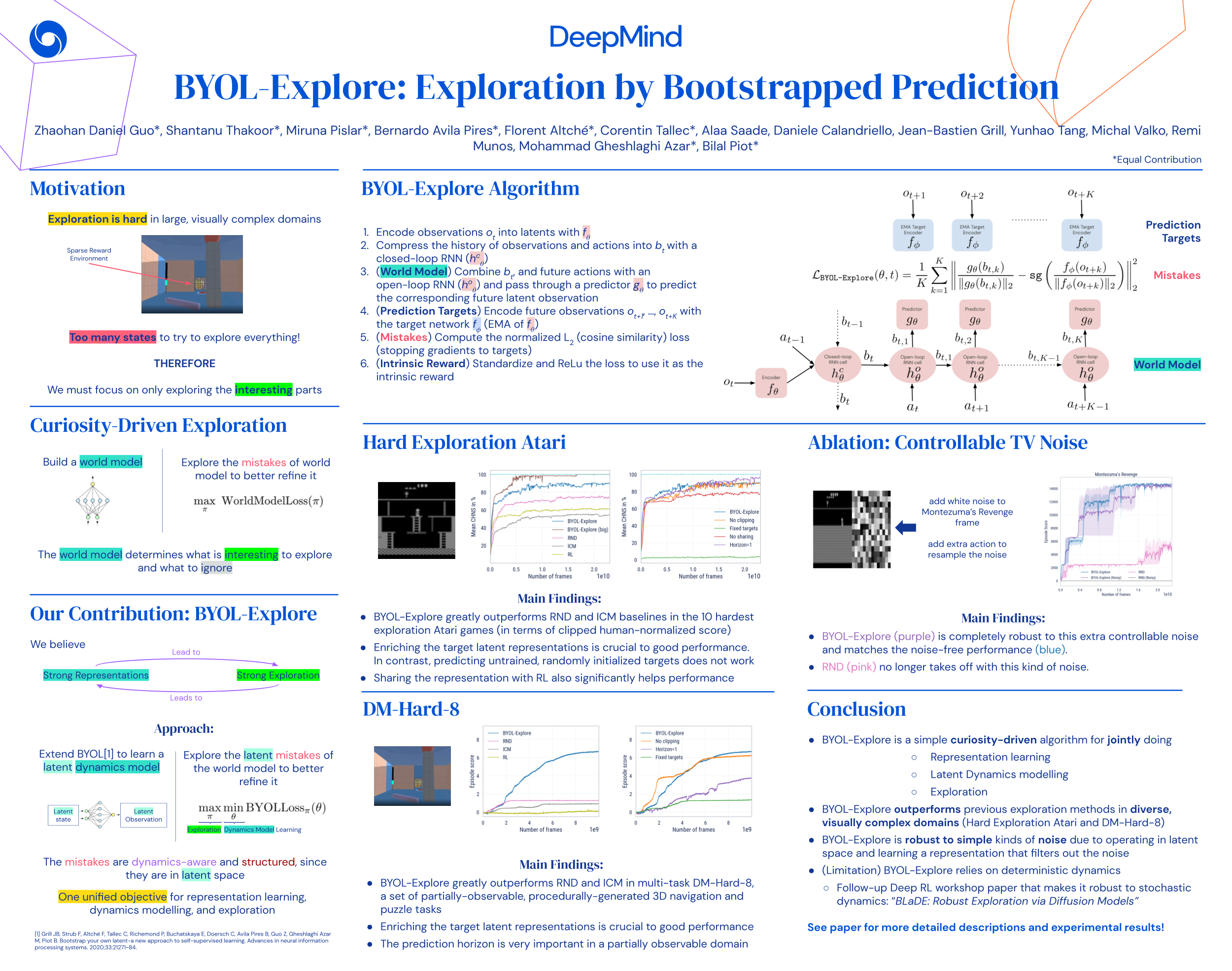
BYOL-Explore: Exploration by Bootstrapped Prediction. Zhaohan Daniel Guo*, Shantanu Thakoor*, Miruna Pîslar*, Bernardo Avila Pires*, Florent Altché*, Corentin Tallec*, Alaa Saade, Daniele Calandriello, Jean-Bastien Grill, Yunhao Tang, Michal Valko, Rémi Munos, Mohammad Gheshlaghi Azar, Bilal Piot. NeurIPS (2022).
When should agents explore?. Miruna Pîslar, David Szepesvari, Georg Ostrovski, Diana Borsa, Tom Schaul. ICLR (2022).
Machine translation decoding beyond beam search. Rémi Leblond, Jean-Baptiste Alayrac, Laurent Sifre, Miruna Pîslar, Jean-Baptiste Lespiau, Ioannis Antonoglou, Karen Simonyan, Oriol Vinyals. EMNLP (2021).
Seeing Both the Forest and the Trees: Multi-head Attention for Joint Classification on Different Compositional Levels. Miruna Pîslar, Marek Rei. COLING (2020).
Talks & Events
- RL tutorial at Indaba, Kigali (July 2025): tutorial link
- RL tutorial at EEML, Sarajevo (July 2025): tutorial link
- BYOL-Explore at NeurIPS Paris event (November 2022): tweet, poster
- Learning Robust Real-Time Cultural Transmission without Human Data at the Cognitive Machine Learning (CoML) group at ENS (November 2022): tweet
- Cultural Transmission in AI at the Machine learning Workshop at EvoLang in Kanazawa, Japan (September 2022)
- When should agents explore? at ICLR (April 2022): tweet, video
- When should agents explore? at MILA RL Sofa (April 2022)
- Transformers: past, present and future at the Virtual Grace Hopper Celebration EMEA (2021): video
- Introduction to Natural Language Processing at a hackathon organised by TeensInAI Romania (2021): tweet
- Interview on my career path at NEstTV show’s “Sinteze Administrative” (2020): Part 1, Part 2 (in Romanian)
{kind=link}
Artistic output
Stories: matca
Poems: agonia
Photos: flickr
Visual projects: behance